Much like a chef tastes a dish as it simmers, data scientists and project managers can use QA/peer review jobs to understand how annotations are taking shape as they progress through various steps in a Workflow.
Note: Workflows currently supports use cases that produce aggregated responses. Jobs containing cml:text, cml:textarea, cml:checkboxes are not officially supported at this time.
Note: For Dedicated customers, this feature is currently not available On-Premises and only available via the cloud multi-tenant Appen Data Annotation Platform.
Before You Start
- Users typically send either n% random samples or all of their data to a QA job for review. The sample size "sweet spot" will vary by use case and how you prefer to balance quality with throughput and costs.
- QA/peer review jobs are always specifically designed to test the output from the source operator. The two most commonly used QA methods are:
-
- Peer Review: display the agg output from the source operator as data for another contributor to peer review and/or correct.
-
-
- Note: Annotation Tools must be set up with the
review-datatag and column outputs/inputs must be mapped to ensure proper routing. Add intask-type= 'qa' OR 'arbitration'. E.g. seereview-datadocumentation for the Shapes tool: Guide to: Running a Shapes Review Job
- Note: Annotation Tools must be set up with the
-
-
- Blind Validation: display the original, unlabeled source data and collect an annotation from another contributor, then compare the results.
- As a reminder, you remain in full control of each job's pay and targeting settings, even when they become connected with Workflows. For example, you have the flexibility to mix job targeting settings such that different Workflow steps are sent to trusted contributors, the open crowd, or your own internal teams for peer review, and can set the payment of each job according to difficulty or expertise requirements.
- All cml elements you wish to route in Workflows must be configured to output "
aggregate" results. In general, it is advisable to setaggregation="agg"on every cml element in any given job to ensure proper routing.
Route Random Samples to QA in Workflows
Use Random Sample routing to send samples of each annotator's work to a QA/peer review job. This feature leverages deterministic sampling to ensure your requested sample size is always fulfilled, no matter how many rows a given contributor completes. This means contributors who've completed more work than others will naturally have more rows routed to QA.
To set up a random sample in the Workflows Canvas:
1. Create a Workflow and connect two operators on the Canvas
- Once the Routing panel slides into view, select Route a Random Sample from the dropdown and input your desired sample size (n%).
- If you do not wish to route the rest of your data (i.e. the non-sampled rows) past this step, that's it! Simply click Save & Close.
2. If you wish to route the non-sampled (ELSE) rows for additional annotations, continue to Step
3. Click the Add Operator button. This button is only available within the ELSE table when you are configuring a Random Sample rule.
4. Drag another operator into the empty dropzone, then click Save & Close to create a branch.
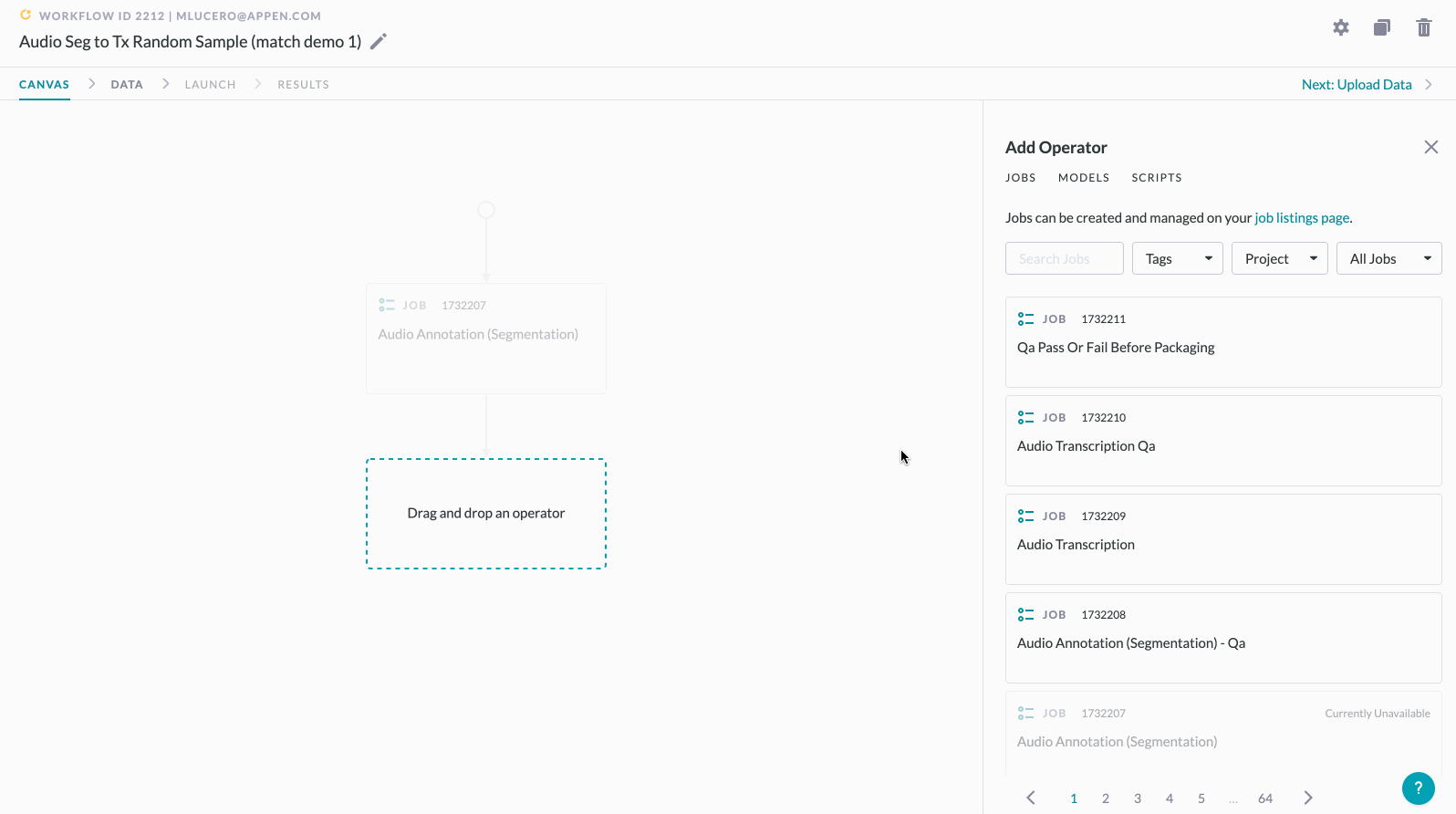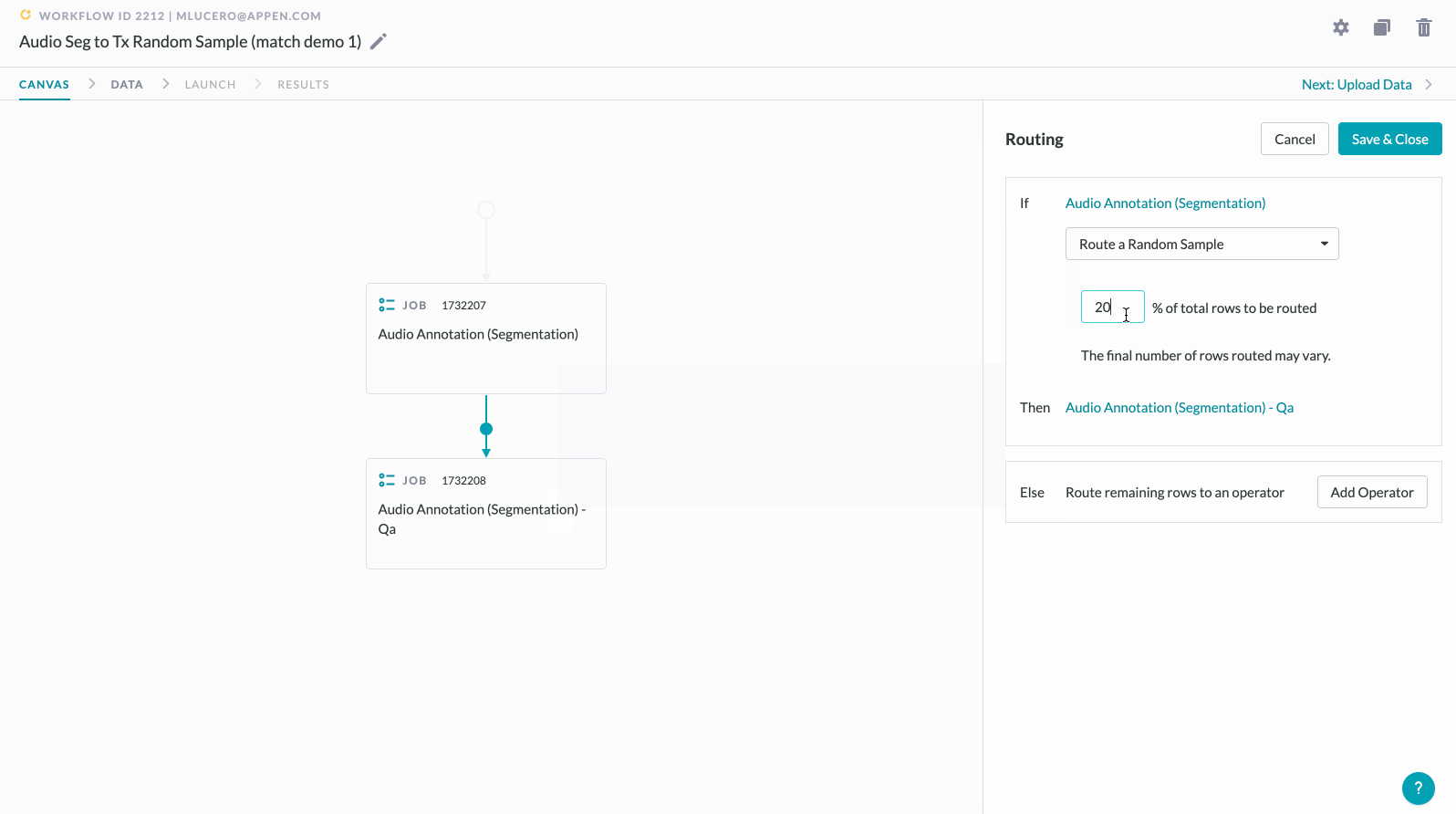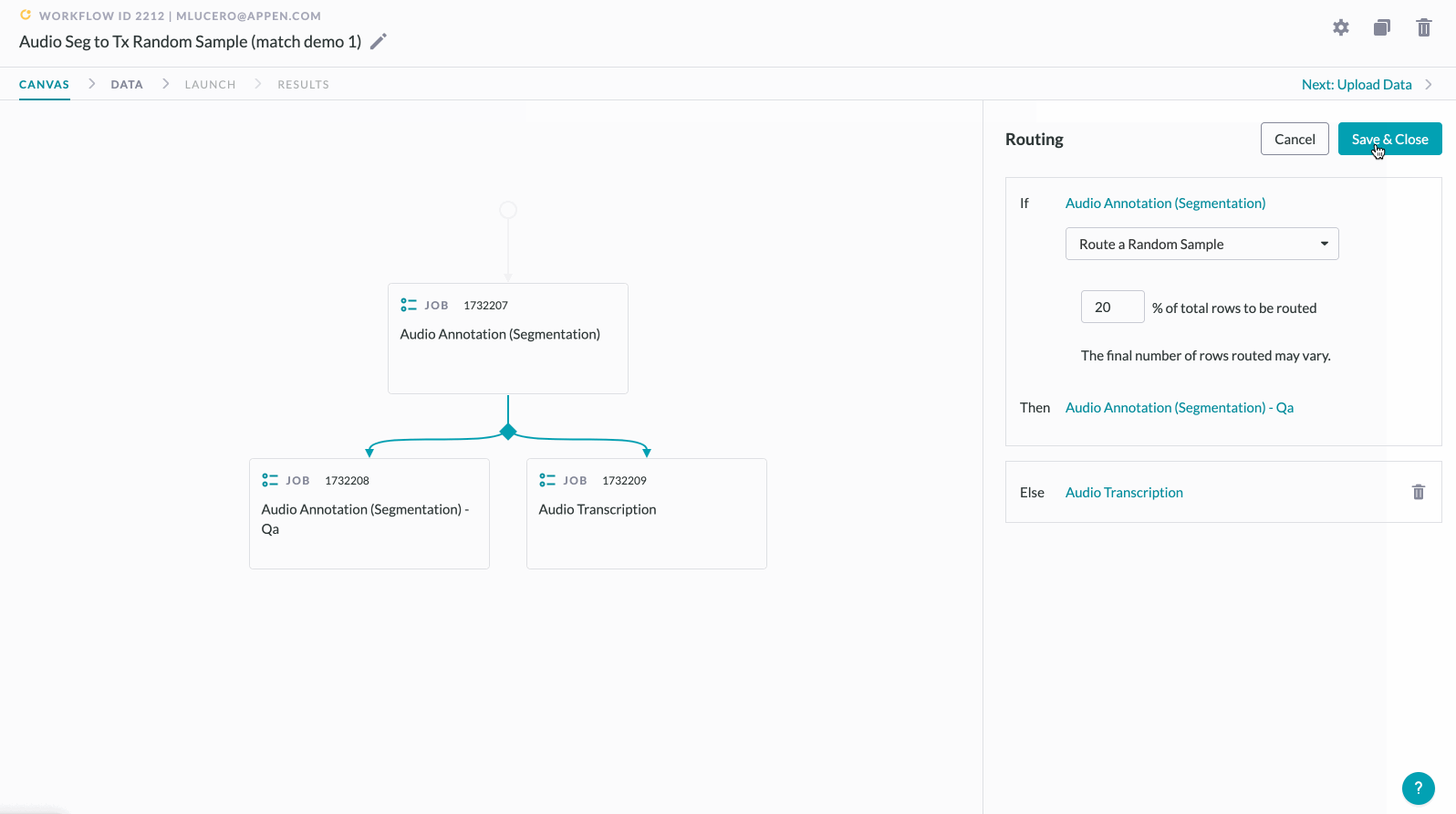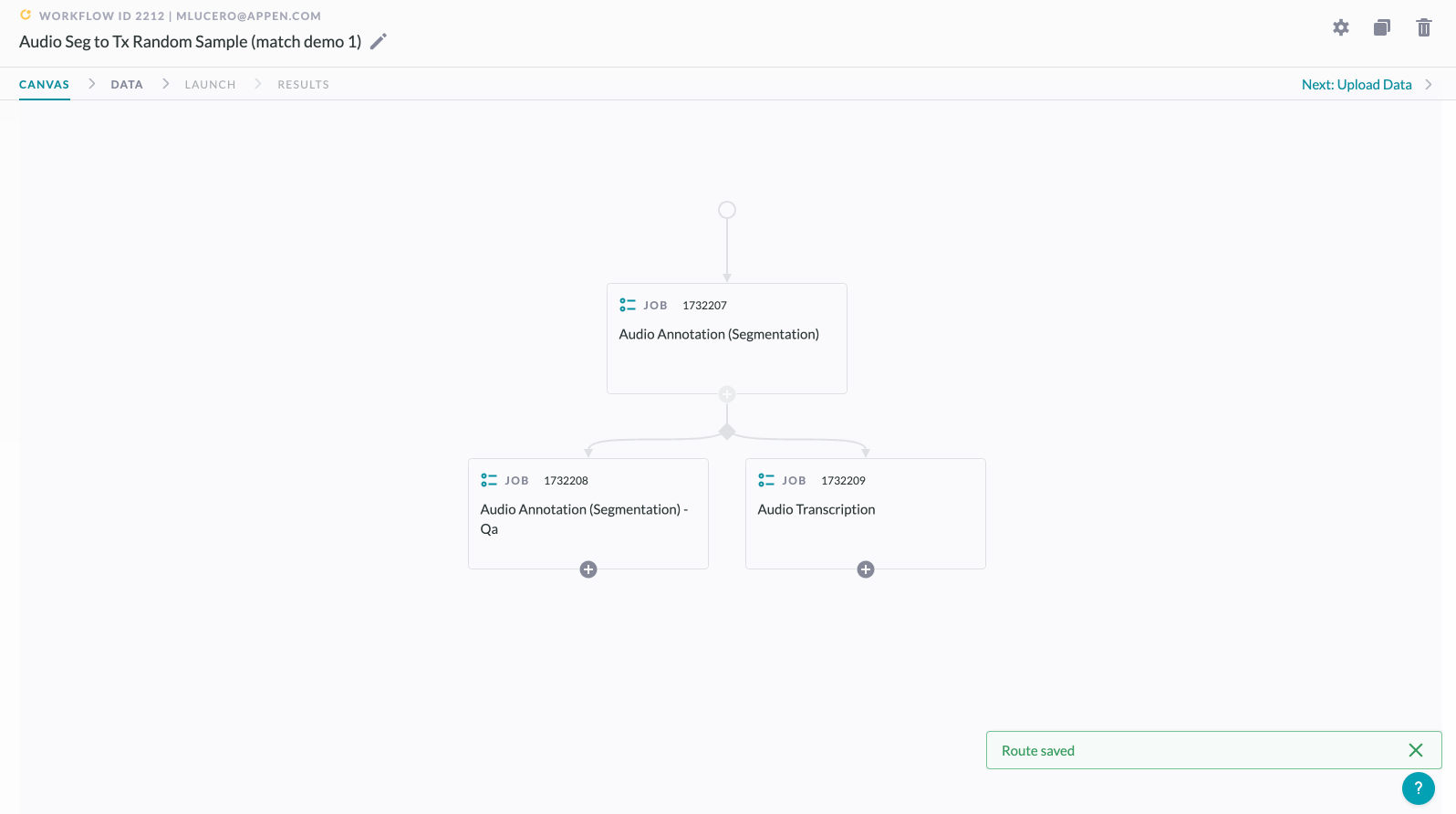
Figure 1
Merging the output of a random sample back together with non-sampled data:
5. Click "+" below the QA/peer review job to add an empty dropzone, which will request a decision.
6. Select the operator you previously placed in the branch, which will merge routing lines on the Workflows Canvas.
7. Select your Routing Method. In this case, you are able to Route All Rows or Route by Column Headers.
8. Click Save & Close.
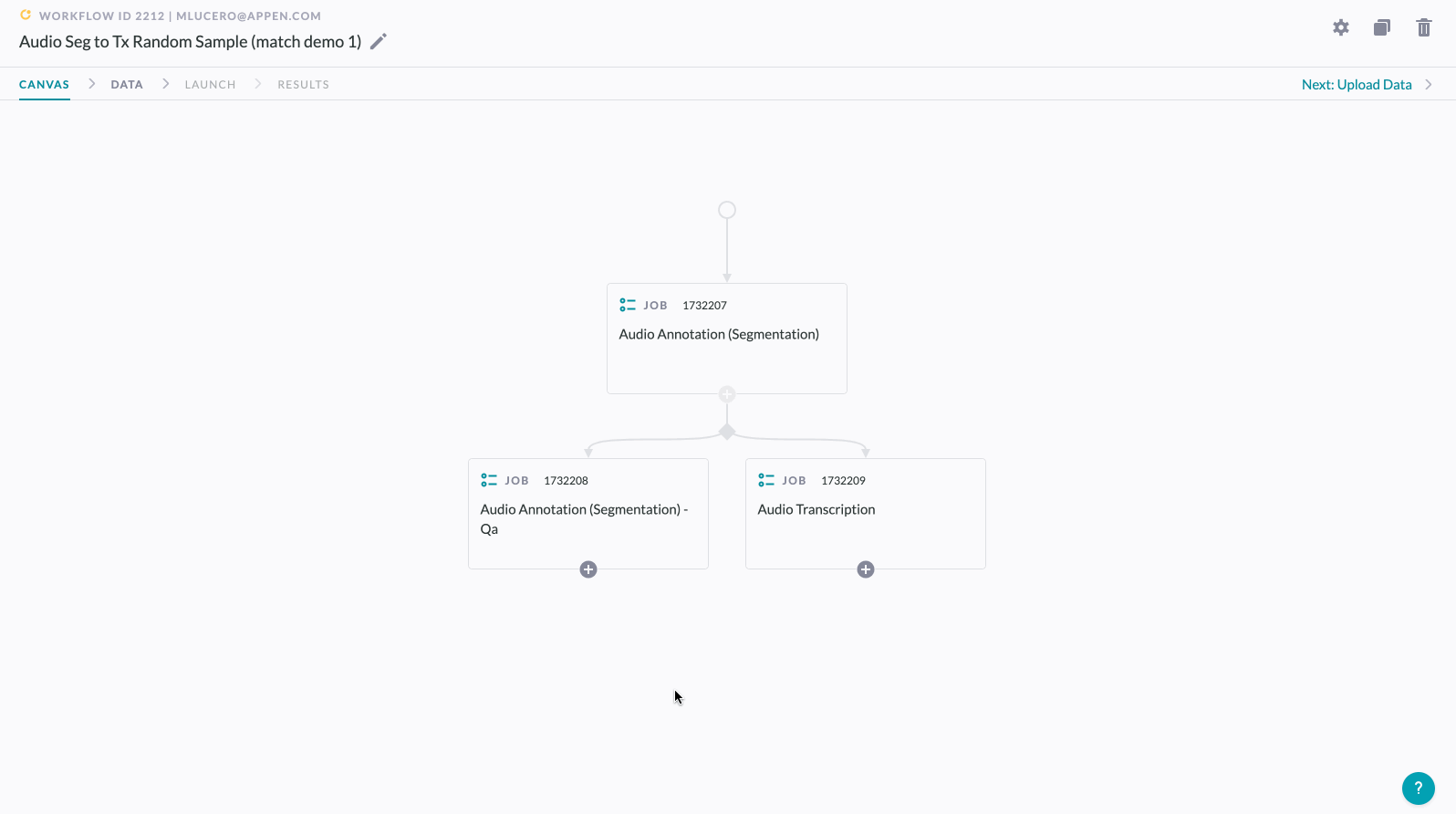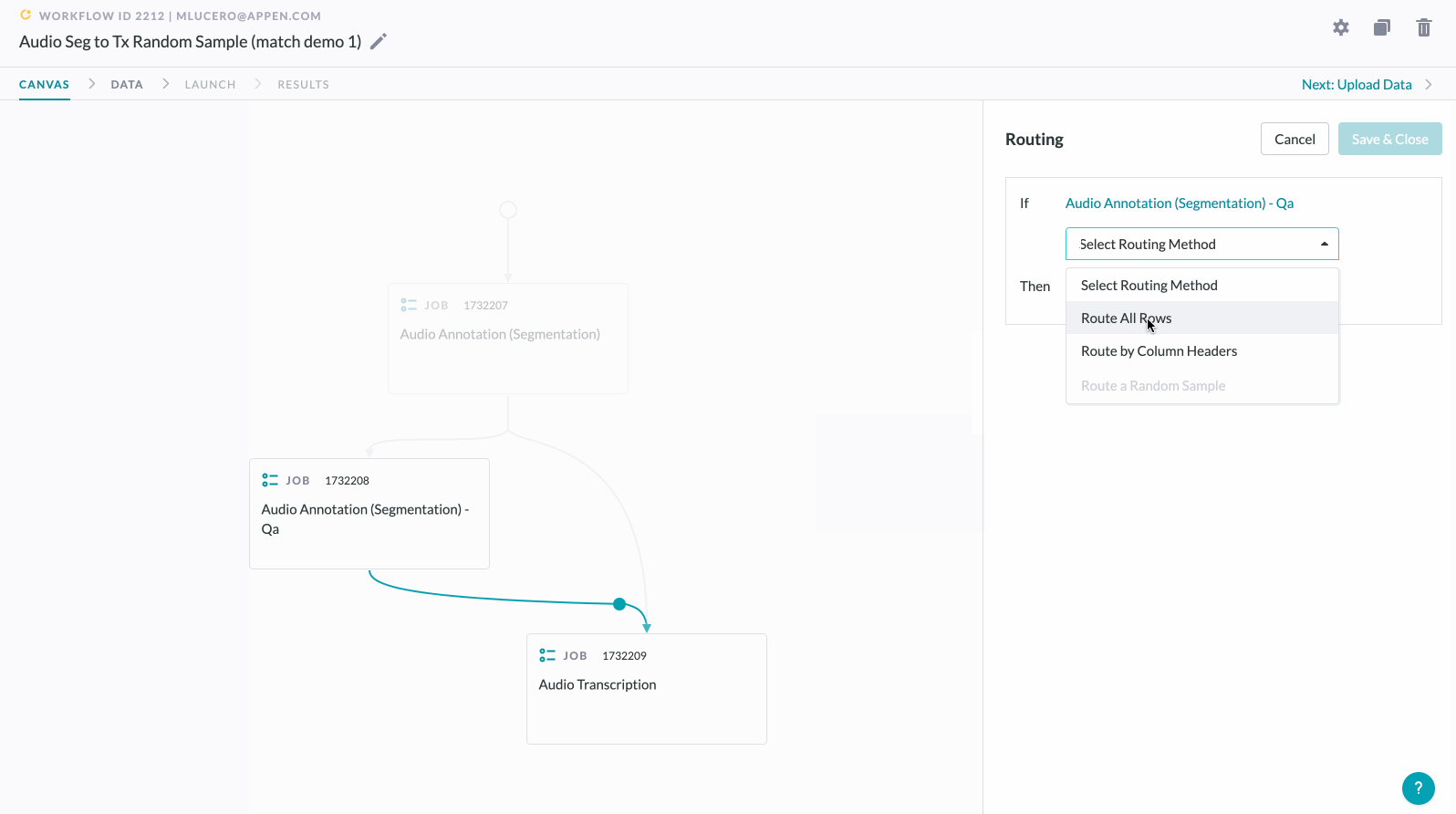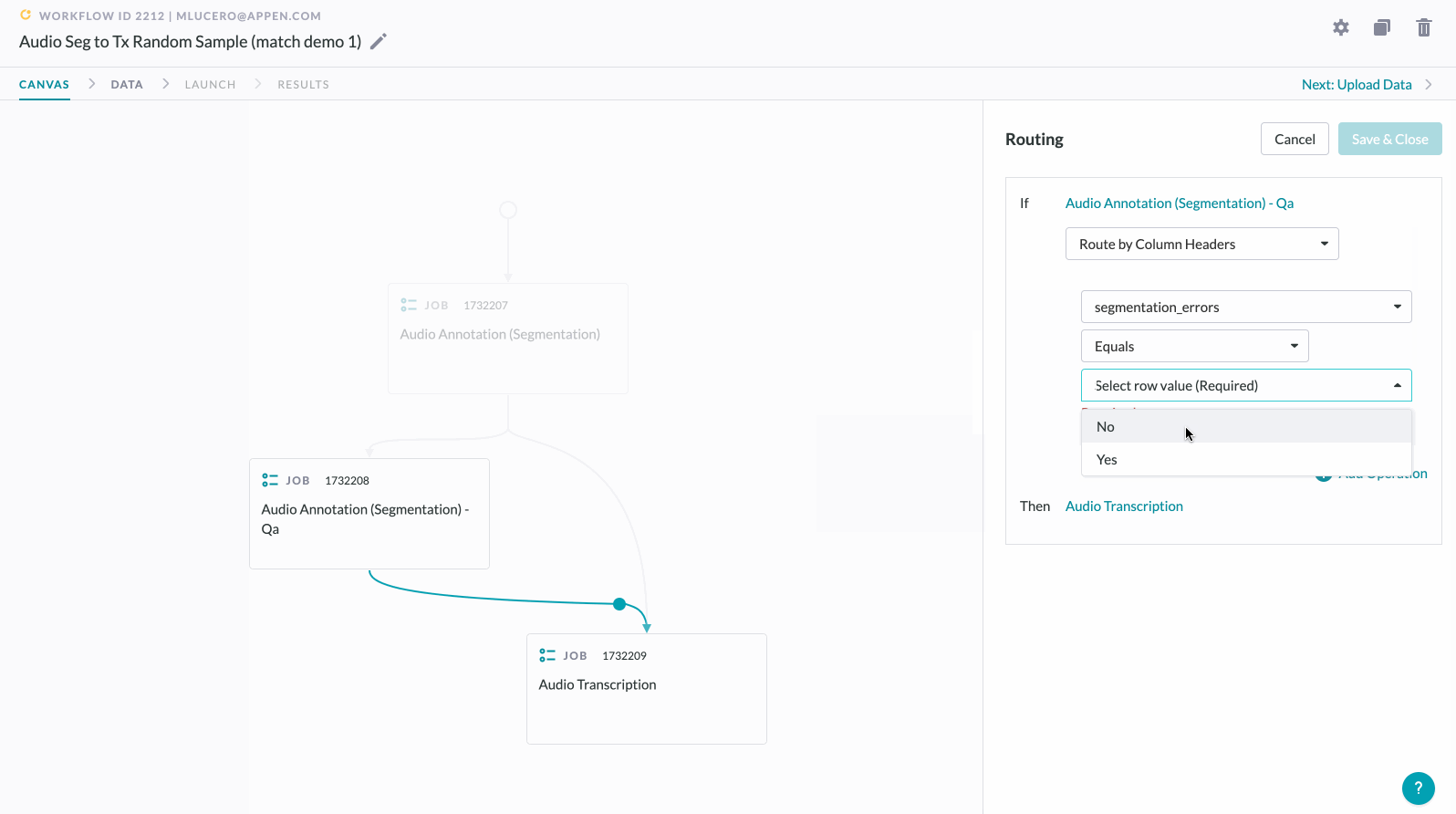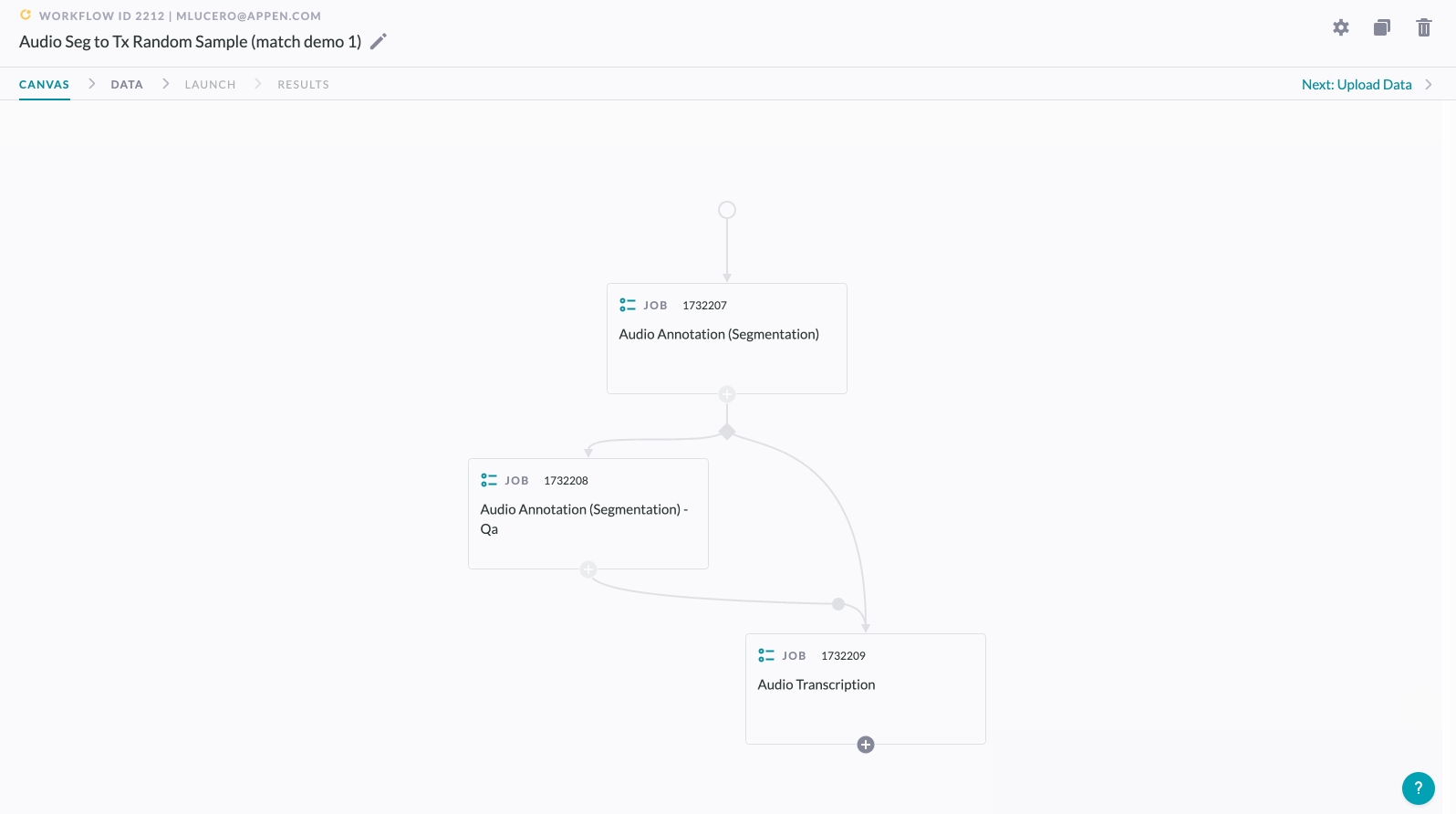
Figure 2
Because Workflows are modular, you have the flexibility of setting up Random Sample/ELSE merges multiple times in your Workflows:
Figure 3
Interpreting Workflow Report Results from Random Sample-to-QA/Peer-Review
In the Workflows Report, you’ll now notice an additional column titled {{job_id}}:worker_id, which corresponds with the contributor that completed work on that unit in the job.
Carefully filter the Workflow Report by worker_id and/or QA/peer review outputs to get a sense for how the overall random sample, or how specific worker_ids’ random samples scored in QA.
For example, if a QA job was configured to receive a 50% sample and output simple “Pass/Fail” annotations as cml:radio output:
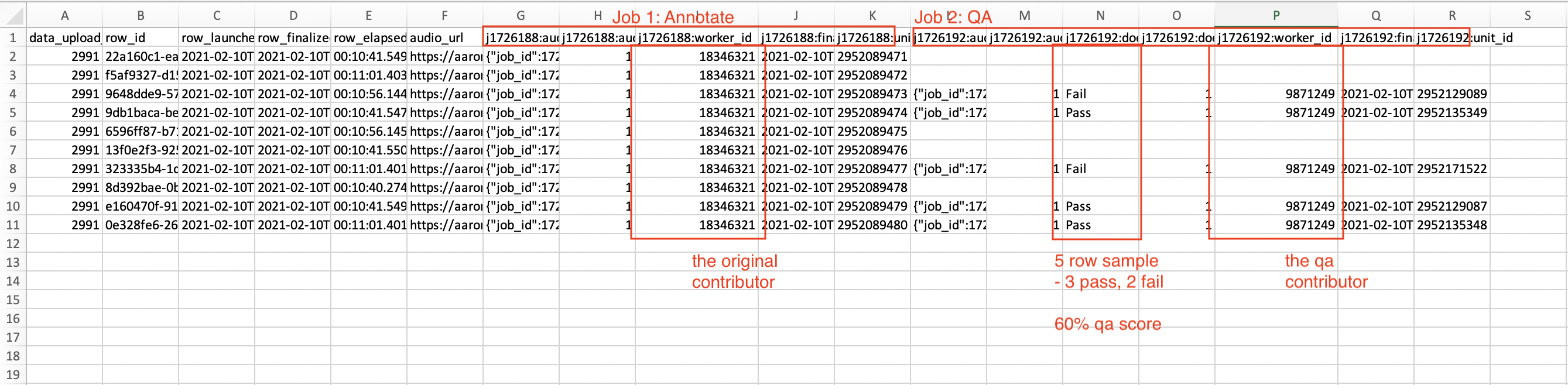
Figure 4
Other considerations:
- Currently, the
worker_idmechanism works best at 1 JPU. In the event that you collect multiple JPU, only the firstworker_idto submit work on the unit will be collected. - On the Jobs/Data page, Workflow-routed rows will contain
worker_idas part of the source data. In this case,worker_idcorresponds with the contributor that completed the row in the preceding step. Under most circumstances, you can expect this id to change with each subsequent step.