Liquid is a template language supported in Appen that allows users to display source data into a job’s user interface.
For more information about Liquid check out this article.

Fig 1. Source data
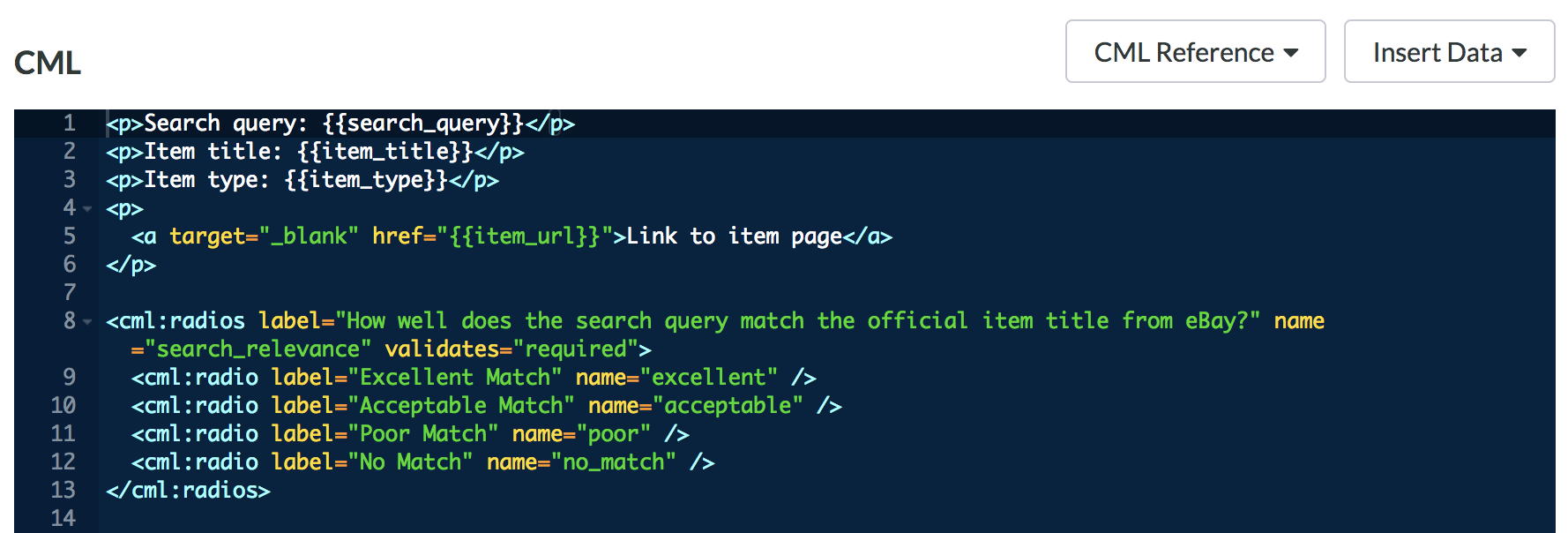
Fig 2. CML calling in a variable from the source data
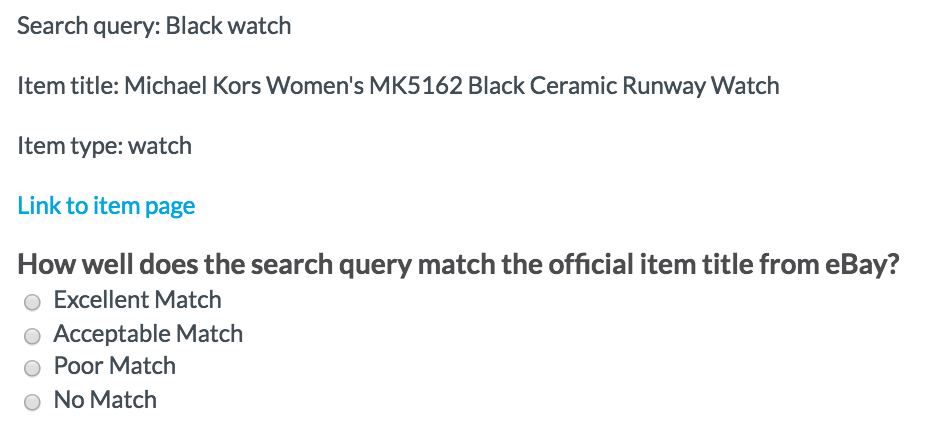
Fig 3. Job design using Liquid
Using Liquid Logic to display questions based on source data
The source data in Fig 1. shows there are two different categories of "item_type": "watch" and "electronic". We want to use different brands for items that are watches and items that are electronics. Rather than splitting this work into two separate jobs, we can display two unique question sets within the same job:
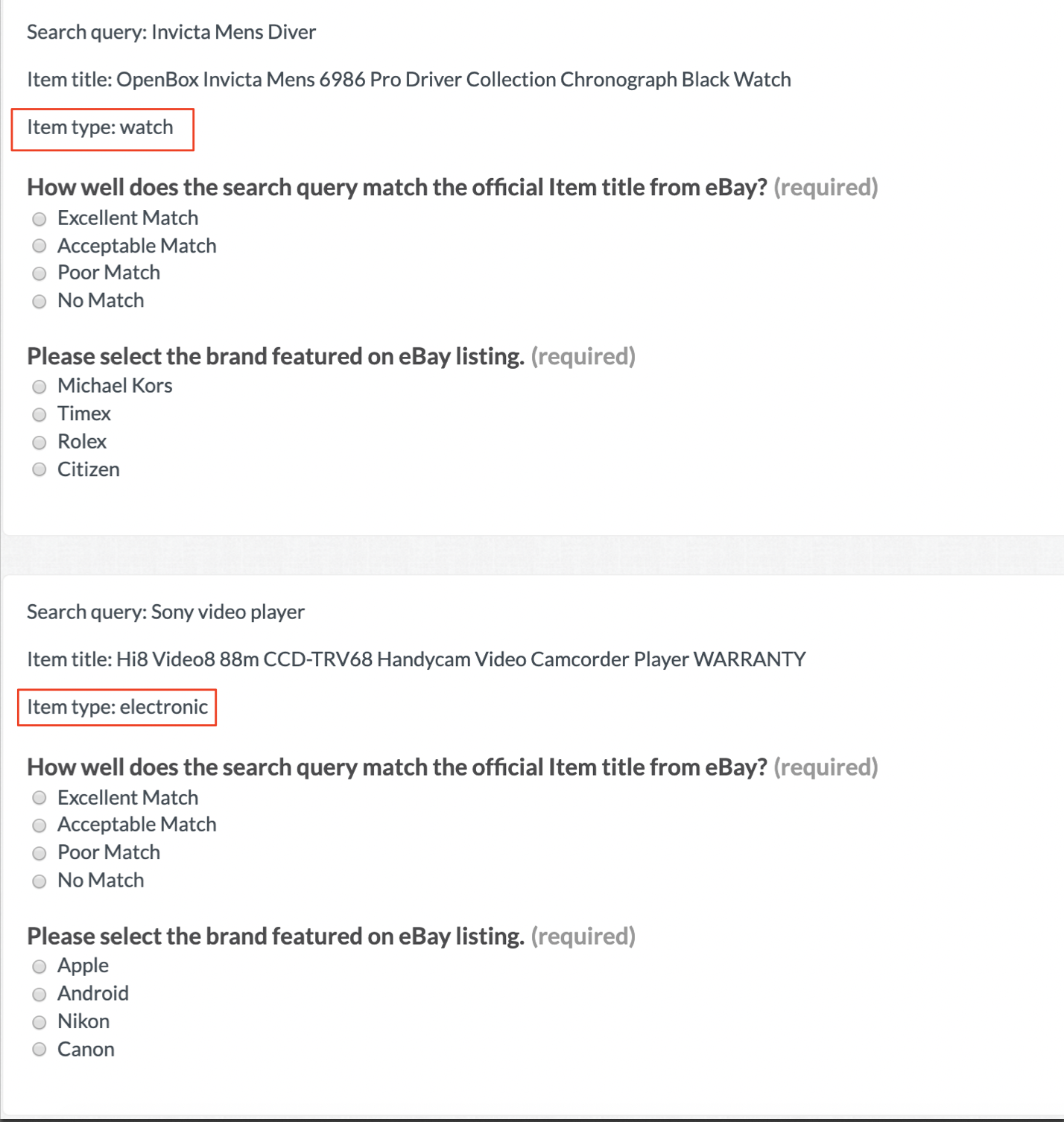
Fig. 4: Preview of the job displaying specific questions based on the source data
Regardless of the "item_type", we want to ask what the relevance of the "search_query" is to the "item_title". This is shown in our first radio question. The code below demonstrates how to alter the second question to be specific to the "item_type":
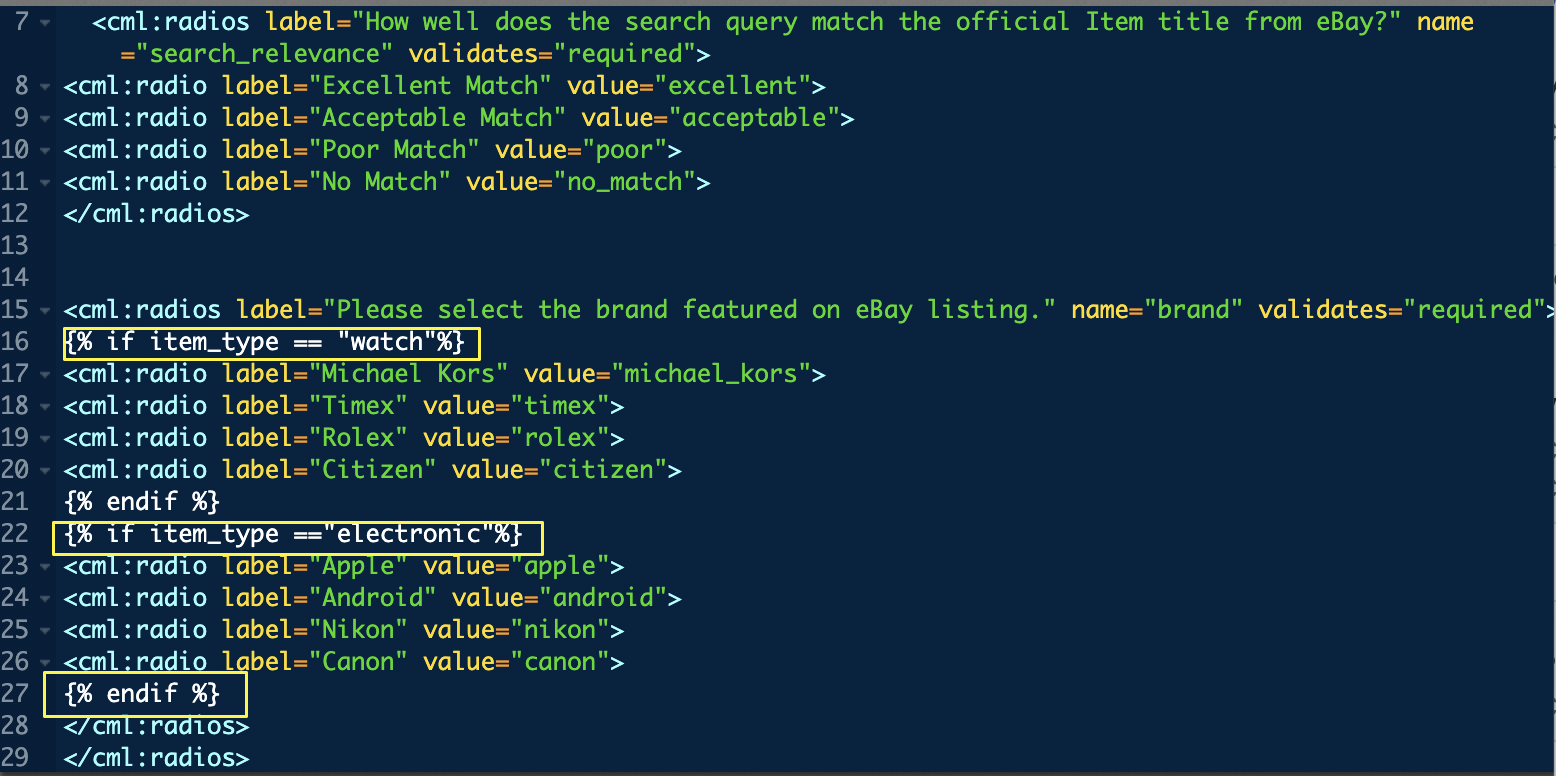
<cml:radios label="How well does the search query match the official Item title from eBay?" name="search_relevance" validates="required">
<cml:radio label="Excellent Match" value="excellent">
<cml:radio label="Acceptable Match" value="acceptable">
<cml:radio label="Poor Match" value="poor">
<cml:radio label="No Match" value="no_match">
</cml:radios>
<cml:radios label="Please select the brand featured on eBay listing." name="brand" validates="required">
{% if item_type == "watch"%}
<cml:radio label="Michael Kors" value="michael_kors">
<cml:radio label="Timex" value="timex">
<cml:radio label="Rolex" value="rolex">
<cml:radio label="Citizen" value="citizen">
{% endif %}
{% if item_type =="electronic"%}
<cml:radio label="Apple" value="apple">
<cml:radio label="Android" value="android">
<cml:radio label="Nikon" value="nikon">
<cml:radio label="Canon" value="canon">
{% endif %}
</cml:radios>
Fig. 5: CML with Liquid logic to show questions based on a specific column
Liquid For-loops: Iterate through a List
Liquid can also be used to iterate through a list in your source data. Rather than having a hard coded list of brand options, let’s say you want to populate the options dynamically from the source data. For example, the column titled ‘possible_brands’ below contains a list of potential brands for each row.

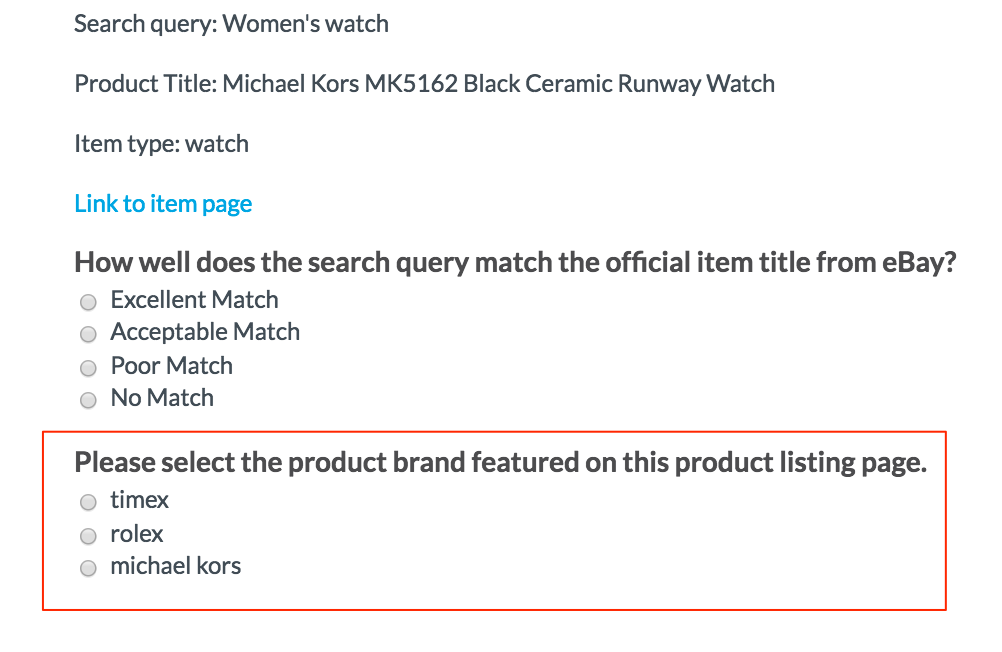
Fig. 7: Job preview using ForLoops
In order to allow the contributor to select from the possibilities in this list, we can use a Liquid loop:

<cml:radios label="Please select the product brand featured on this product listing page." name="brand" validates="required">
{% for brand in possible_brands %}
<cml:radio value="{{possible_brands[forloop.index0] }}" label=“{{ brand | replace:'_',' ' }}" />
{% endfor %}
</cml:radios>
Fig. 8: CML with Forloops
Note: We first create a Liquid variable, named "brand", to refer to each item in the column "possible_brands". For example, in a single row, the column named "possible_brands" contains the data "timex, rolex, michael_kors", where each type of brand is listed in the data cell.
There are a few things to note about the Liquid within the cml:radio tag:
value="{{ possible_brands[forloop.index0] }}"- The value is referencing the column "possible_brands" and the index of the forloop iteration, with the index starting at 0
- The radio value must reference the column header instead of the Liquid-generated variable, "brand"
label="{{ brand | replace:'_',' ' }}"- The label is referencing the Liquid forloop-generated variable "brand"
- The "replace" Liquid filter is used to replace all occurrences of an underscore with a space
Important: In order for ForLoops to work, we'll need to click "Split Column" on the top Data page. Once clicked, select the column you want to split and add the delimiter you want to split the column on. This will convert each cell in that column into an array based off a specified delimiter.
What if the source file has some missing data points?
Source data can sometimes be incomplete and in this case, we can use Liquid logic to hide the missing data from the job design to reduce confusion.

Fig. 10: Source data with missing ‘possible_brands’ data
Instead of displaying ‘No data available’, we can hide these fields that are empty. The following code will hide the "possible_brands" question on the rows it’s empty.
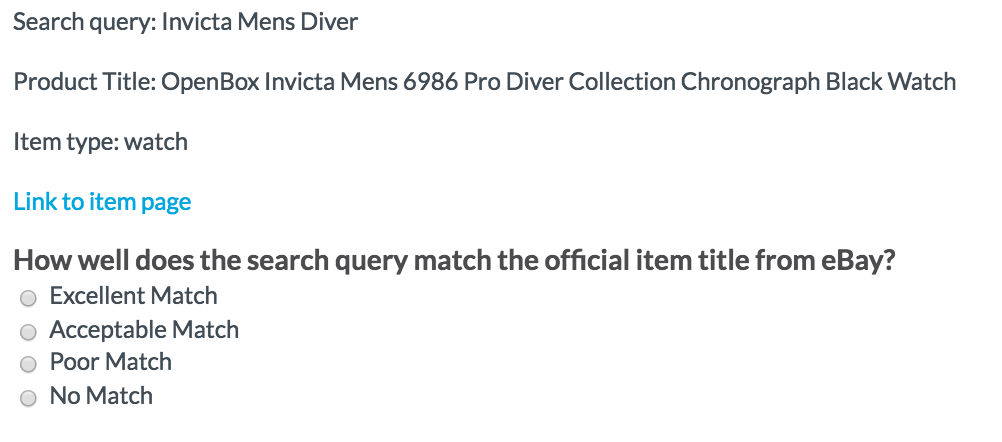
Fig. 11: Hidden possible brands question using Liquid logic

{% if possible_brands != 'No data available' %}
<cml:radios label="Please select the product brand featured on this product listing page." name="brand" validates="required">
{% for brand in possible_brands %}
<cml:radio value="{{possible_brands[forloop.index0]}}" label="{{ brand | replace:'_',' ' }}" />
{% endfor %}
</cml:radios>
{% endif %}
Fig. 12: CML with Liquid to hide question when there is no source data to display
When using Liquid for-loops, make sure to include the JavaScript function below in the Javascript editor on the Design page. This code snippet will ensure you can update test questions in the user interface without any issues.
var showGold = function(){
var data = $$('form').retrieve('gold')[0].options.unitData;
$$('.checkboxes').each(function(cb){
cb.getElements('input').each(function(input){
var answers = data[input.get('class').split(" ")[0]];
if ( (answers == input.value ) || (Array.isArray(answers) && answers.contains(input.value))) {
input.checked = true;
input.fireEvent('change');
}
})
})
}
if(_cf_cml.digging_gold) {
showGold.delay(100)
}